Blocking Feed Pages from Robots.txt
In this case, it is aimed to improve the crawling budget as a result of blocking the "feed" pages on our website via robots.txt and leaving them out of crawling.
Problem
Data
Method
Results
Is it possible to improve crawl budget by blocking feed pages from robots.txt?
We tried, yes!
We have experimented to make sure that our wordpress pages with /feed slug, which are constantly crawled by Google bots, are not crawled and to make room for our important pages in our crawl budget.
As the first step of this experiment, blocking was done using the /*/feed* regex structure from the robots.txt file of the feed pages in question.
Afterwards, 15 days were waited to wait for the results of the experiment.
The first experiment was conducted on 21.11.2023.
The data obtained as a result of the experiment is as follows;
- Feed structure was not scanned in any way after blocking.
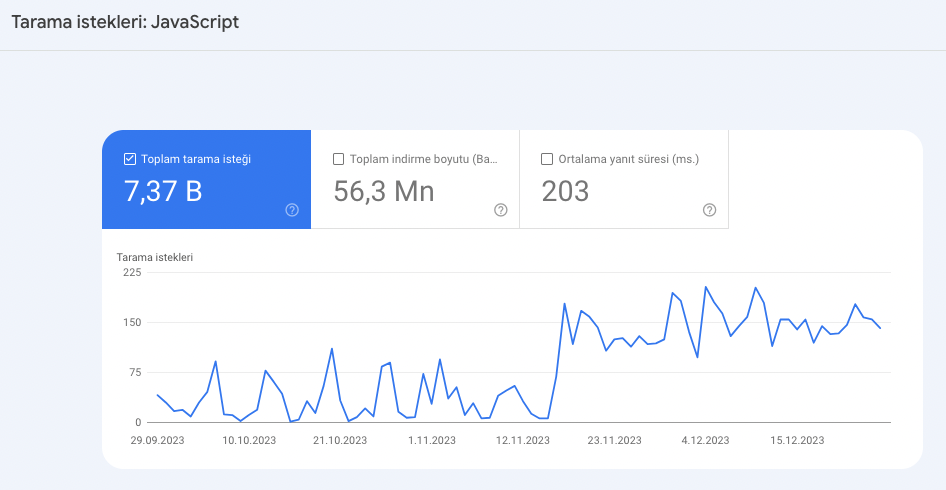
- The number of JS and CSS files scanned increased significantly after the blocking.
- The number of HTML files crawled increased slightly after the trial.
- The speed at which important pages are re-crawled or newly discovered has increased.
- You can access the images related to the trial below.
To give our opinions about the case, the feed pages on WordPress do not provide very serious and valuable information. If the feed structure on the website is not used for a different purpose (such as sitemap), then I think that blocking feed files will not be harmful and on the contrary, it will be beneficial.